ForkJoin
Fork/Join框架是什么
Fork/Join框架是由并发大师Doug Lea所开发的一种新增并发编程模型,它提供了一种通过(递归的)把问题划分为子任务,然后并行的执行这些子任务,等所有的子任务都结束的时候,再合并最终结果的这种方式来支持并行计算编程的模型。此模型已经成为了许多JDK功能所依赖的基础,其中包括:JDK8所提供的Stream,ComputableFuture以及JDK9中所提供的FlowAPI等。
该框架所包含的类主要有:
- ForkJoinPool:Fork/Join框架的调度器
- ForkJoinTask:Fork/Join框架执行任务的抽象
- RecursiveAction:ForkJoinTask的子类,用于处理没有返回值的计算
- RecursiveTask:ForkJoinTask的子类,用于处理有返回值的计算
Fork/Join框架诞生的背景
在Fork/Join框架出现前,对于一个递归任务,我们通常采用的方式是直接调用递归算法处理它,这里以统计某目录下的文件数量为例,代码如下:
public static Integer countFile(File root) {
//递归退出条件:root为文件
if (root.isFile()) {
return 1;
//如果root为目录,则需要递归统计该目录下的所有目录与文件
} else {
int sum = 0;
for (File file : root.listFiles()) {
sum += countFile(file);
}
return sum;
}
}
代码将以单线程方式递归处理root目录,直到统计出该目录下含有的文件总个数为止。
如果某个目录下的文件数量特别大,导致该任务执行时间很长,我们应如何优化此类计算?
并行化
上述代码执行起来最大的瓶颈在于只能单线程运行,不能充分发挥多线程的优势。考虑文件目录结构如下(不考虑目录树出现回环的情况):
如上图所示,root目录下含有多个目录,此时如果能够采用并行方式在线程1,线程2…上分别调用countFile(dir1),countFile(dir2)…就能充分利用CPU资源,利用多核的性能优势能够大大减少程序所运行的时间。使用代码表示如下:
public static Integer countFileRoot(File root) {
if (root.isFile()) {
return 1;
}
AtomicInteger sum = new AtomicInteger(0);
CountDownLatch countDownLatch = new CountDownLatch(root.listFiles().length);
for(File file : root.listFiles()) {
//并发执行
new Thread(new Runnable() {
@Override
public void run() {
sum.getAndAdd(countFile(file));
countDownLatch.countDown();
}
}).start();
}
countDownLatch.await();
return sum.get();
}
负载均衡
上面的parallelCount方法存在严重的缺陷:各工作线程所分得的任务不均匀。考虑目录树结构如下所示:
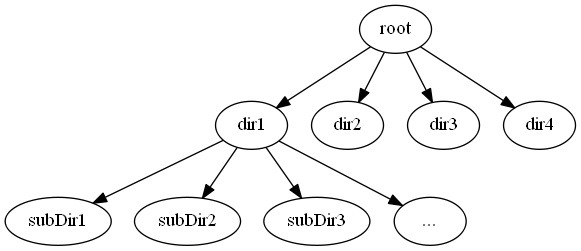
其中dir2,dir3,dir4均是空目录,所有的计算量仍然集中于运行countFile(dir1)的线程上。其执行效率与单线程递归并无多大提升,由于创建了多个线程,效率甚至还不如单线程递归模式。此方案效率不高的最根本原因是:海量任务集中于某一个线程上,其他工作线程处于闲置状态,结果仍然是无法充分利用CPU资源。

如果能够将所有的任务平均分给许多工作线程, 这样执行起来岂不很棒?以自然语言的方式描述起来如下:假设我们有一个任务池存放着所有的工作任务,每个线程按以下方式进行工作:
- 从任务池中获取一个任务,按以下方式进行计算
- 如果任务所依赖的子任务全部计算完成,该任务可直接计算得到结果,则直接执行,然后回到1
- 如果任务需要被划分为若干个更小的任务,则将这若干个更小的任务全部放入任务池,等待这些小任务完成之后计算得到结果,然后返回1
- 反复执行该过程直到所有任务执行完毕
这与线程池的语义不是差不多吗?这个简单
//由于要阻塞等待subTask的完成,所以必须使用无界的newCachedThreadPool
private static ExecutorService threadpool = Executors.newCachedThreadPool();
public static Integer countFileByTask(File root) {
if (root.isFile()) {
return 1;
}
List<Future<Integer>> futures = new LinkedList<>();
for (File file : root.listFiles()) {
Future<Integer> future = threadpool.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
return countFileByTask(file);
}
});
futures.add(future);
}
int sum = 0;
for(Future<Integer> future : futures) {
sum += future.get();
}
return sum;
}
想法很丰满,现实很骨感。经过试验,这种执行方式的效率是所有执行方式中最慢的。
仔细分析countFileByTask方法:其核心计算逻辑只有一个return 0以及将各子任务的值进行累加,但是却引入了对每一个子目录/文件创建Thread的过程!创建Thread的开销远远大于简单累加的开销,更不用说当Thread实例数量爆炸之后操作系统调度所带来的开销以及GC的时间开销。
Fork/Join框架通过work-stealing一整套解决方案来解决这个问题。对于上面的目录树,我们分别画出各工作线程的递归堆栈,如下:
1.有4个工作线程,每个线程分别负责root下一个子目录的工作

2.thread1-3迅速完成了自己的工作,但是thread0仍有许多子任务需要处理
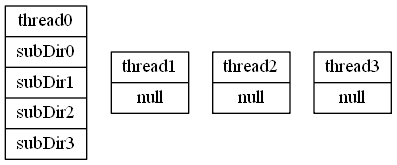
3.step1阶段的thread2,thread3,thread4执行完成后,任务栈就空了,但是thread1的任务栈中被压入了countFile(subDir0),countFile(subDir1),countFile(subDir2),countFile(subDir3)三个任务。在ForK/Join框架下,此时任务栈为空的线程将尝试从thread1中获取task,并放入到自己的任务栈中当作自己的task并以递归的方式运行。这样的行为感觉像是从其他线程的task栈中偷取了一个任务来运行,所以被称为work-stealing。偷取之后的任务栈如下所示,通过这样的方式就实现了子任务在各线程间的平均分配。

Fork/Join框架的实现细节
上一节主要讨论了Fork/Join框架的总体思路,这一节将介绍框架实现中的部分关键细节
两种Work-Stealing方式
什么样的worker线程需要从其他线程的工作queue中偷取task?答案很简单:当前taskQueue为空的worker。taskQueue为空有两种情况:1.worker的工作队列为空,所有任务执行完成;2.worker所fork的任务被其他worker所偷走了,当前worker处于join等待,但是工作队列却无task可用。
对于第一种情况,由于worker“无事可做”,所以从其他任意worker处偷取一个task放入自己的taskQueue执行即可。
对于第二种情况,如果从其他任意worker偷取task就可能会出现问题。假设情况如下:
- task1任务被提交至ForkJoinPool中
- worker1获取到task1并开始执行
- 在worker1执行task1的过程中调用了task3,fork(),worker1将task3放入自己的工作队列,此时worker2将task3偷走并执行
- 当worker1执行到task3.join()时,发现自己的taskQueue中无任务可执行了,从其他任意taskQueue中偷取到了刚被提交至pool中的task2
这种情况下,只有当task2被执行完成后才能执行完成task1。等价于在执行task1的过程中调用了task2.join(),或者说task2成为了task1递归中的一部分。但是在代码逻辑中task1与task2是完全独立的两个任务!由于框架的运行导致这两个task之间有了依赖关系。这样的话task1在执行过程中被反复添加多个task的依赖,会导致task1迟迟得不到返回。
对于调用task.join()方法而进入”空闲”状态的线程在进行work-stealing时,只有偷取由该task所fork出来的子任务以及子任务的子任务(递归)才是安全的,这样就能保证执行当前task时,不会插入其他的task“污染”当前task 的执行。因此,调用task.join()方法而进入”空闲”状态的worker线程,它会扫描整个pool的所有taskQueue,找到哪些Queue中的任务是从自己当前join的task中所fork出来的,然后偷取这些queue中的task并执行。
双端队列
work-stealing最核心的问题是:如何避免冲突?如果steal与当前线程都从栈顶获取任务,可预料的这样会造成大量的资源竞争导致系统整体性能降低。Fork/Join框架采用了一种很巧妙的方式来避免工作线程与偷取线程之间的资源竞争–双端队列。
双端队列是一种既支持先进先出又支持后进先出的队列,工作线程使用后进先出的方式获取task(工作起来就像一个栈),其他偷取线程将使用先进先出的方式获取task。该数据结构巧妙的地方在于三点:1.一定层面上避免了工作线程与偷取线程之间的竞争,只有当双端队列中仅含一个元素时才会存在竞争关系;2.越早进入queue的task对应递归树中的层数越高,其工作量也就可能越大,这样steal线程偷取并运行task的时间足够长,不用频繁调用偷取逻辑导致资源竞争;3.一定程度上保证了工作线程的本地性,使得工作线程访问数据的效率有所提高。
TaskQueue
如果要将一个task提交至ForkJoinPool中运行,应该如何处理?如果将该task随便放入一个taskQueue中,如果此时该queue所绑定的worker正在处理其他task,会造成与上一节相同的问题:即将这个task随机join到了其他的task之中。安全的做法是将task放入没有运行task的worker所使用的queue中,这样操作所带来的问题在于:如果所有的worker都忙于处理task,那么提交task的方法将会一直阻塞,直到有worker线程空闲才会返回。
更好的设计方案自然是把提交的任务放到一个地方,当worker空闲之后自己来拿就好了。结合work-stealing特性,ForkJoinPool会创建一些特别的queue:它不被任何一个worker线程所持有,并且保存的是非worker线程所提交的task。当worker线程空闲下来后,它们也会从这些queue中偷取任务并执行,这样的queue就被称为SharedQueue,相对的,与worker线程所绑定的queue被称为privateQueue。ForkJoinPool使用数组来保存所有的queue,其中下标&1 = 1的queue均为privateQueue。
CommonPool
如果我们有n个ForkJoinTask需要执行,是把所有Task丢入一个ForkJoinPool执行好还是为每一个Task单独创建一个ForkJoinPool执行好?答案肯定是将所有的task放入一个大pool中执行更好,原因是创建的ForkJoinPool对象以及Thread对象更少,更加节约系统资源,同时避免了多Thread调度所带来的系统开销,计算这些task使用一个pool比使用多个pool使用的时间会更少。将该情形推广至整个JVM运行过程,也就是说在JVM运行的过程中,仅需要一个ForkJoinPool就够了,而且比创建多个ForkJoinPool效率更高。这就是ForkJoinPool.commonPool的由来,它是一个static类型的ForkJoinPool,共享给整个JVM中所有ForkJoinTask所使用。
Fork/Join框架的使用方式
Fork/Join框架适用于分治算法和递归算法,从本质上来说,它是一种高效率的并行递归算法框架(分治算法本质也是通过递归进行求解)。它的典型用法如下:
Result solve(Problem problem) {
if (problem is small) {
directly solve problem
} else {
split problem into independent parts
fork new subtasks to solve each part
join all subtasks
compose result from subresults
}
}
fork操作将启动一个新的子任务,join操作会一直等待直到所有的子任务都结束。像其他分治算法一样,Fork/Join框架总是会递归的、反复划分子任务,直到这些子任务足够小。这里足够小的标准是指:创建/调度更小任务的成本大于以单线程方式直接执行的成本,也就是说划分子任务并并行执行的时间比单线程执行更慢。请注意,Fork/Join框架中的task仅会阻塞在join处,在其他任何时候都不应该被阻塞。
这里以计算斐波那契数列第n项值的经典问题为例向大家介绍Fork/Join框架的使用方式。斐波那契数列指的是这样一个数列 1, 1, 2, 3, 5, 8, 13, 21,从第二项开始每一项都是前两项之和,它属于一个典型的递归算法。普通递归方式求解的代码如下:
public static Integer fibonacci(Integer n) {
if (n < 2) {
return 1;
} else {
return fibonacci(n - 1) + fibonacci(n - 2);
}
}
将其改写为调用Fork/Join框架形式,使其可以行,代码如下:
public class Fibonacci extends RecursiveTask<Integer>{
private Integer n;
public Fibonacci(Integer n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n < 2) {
return 1;
} else {
Fibonacci subTask1 = new Fibonacci(n - 1);
Fibonacci subTask2 = new Fibonacci(n - 2);
subTask1.fork();
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
}
但是上面代码的执行效率并不够高。考虑执行Fibonacci(2)的情况,此时上述代码会创建两个subTask分别计算Fibonacci(2)和Fibonacci(1),每一个任务的都涉及到创建任务对象,将任务对象push到taskQueue中,再从taskQueue中将task拿出来再执行….其中可能还会涉及到线程之间的竞争,各种条件的验证等。但是其实际计算只有一个简单的判断与返回,将其并行化所带来的开销远远大于了并行执行计算所节约的时间。在这种情况下,并行反而导致计算的效率更低。所以有必要限制一下subTask的大小,当拆分并行所带来的收益小于拆分过程所带来的开销时,就直接执行任务,不再拆分并行。如下:
public class Fibonacci extends RecursiveTask<Integer>{
/**
* 每一种算法的THRESHOLD值都不一样,该值是通过大量测试得到的
*/
private final static Integer THRESHOLD = 13;
private Integer n;
public Fibonacci(Integer n) {
this.n = n;
}
@Override
protected Integer compute() {
//子任务足够小时,直接在当前线程内执行计算
if (n < THRESHOLD) {
return calculate(n);
} else {
Fibonacci subTask1 = new Fibonacci(n - 1);
Fibonacci subTask2 = new Fibonacci(n - 2);
//请注意下面几行各subTask方法的调用顺序
subTask1.fork();
subTask2.fork();
//return subTask2.join() + subTask1.join();更好
return subTask1.join() + subTask2.join();
}
}
private Integer calculate(Integer val) {
if (val < 2) {
return 1;
} else {
return calculate(val - 1) + calculate(val - 2);
}
}
}
上面的代码还有一个小细节需要注意:subTask的fork、join顺序。当前顺序为:subTask1.fork() -> subTask2.fork() -> subTask1.join() -> subTask2.join(),事实上更好的顺序应为:subTask1.fork() -> subTask2.fork() -> subTask2.join() -> subTask1.join()。即join的顺序应与fork顺序相反,以栈的方式对这些task进行调用效率最高。原因如下:
- 便于线程本地化,充分利用缓存。由于刚调用了subTask2.fork(),所以与subTask2相关的数据更有可能仍存在于缓存之中,join时从缓存中拿到计算数据的可能性更大。
- 便于work-stealing。以第一种顺序执行时,由于join的subTask并不在workQueue的栈顶而是在栈底,因此当前线程也会尝试从栈底获取subTask1,同时,其他worker偷取也是从栈底开始。这样一方面会导致获取任务时线程之间的冲突会增加,另一方面会导致subTask1更有可能被其他线程所偷走并执行,当前worker发现subTask1被偷走了,又会去stealer那里偷取线程执行,会执行许多次不必要的steal操作
- 不会增加无用操作,如果所执行的subTask既不在taskQueue的头部也不在尾部,join的时候会创建一个空task对其进行替换,再执行
Fork/Join框架使用注意事项
为了方便大家能够正确使用Fork/Join框架,特意整理了以下几点注意事项供大家参考:
- ForkJoinTask必须合乎规范!!!即ForkJoinTask不能有任何外部中断,最好除了join处逻辑上的blocking之外,不要有任何blocking的地方,包括synchronize关键字所导致的blocking!因为ForkJoinTask一般都是提交到ForkJoinPool.commonPool中执行,处于blocking状态中的线程不能像join那样执行其他任务,也就是说该worker线程什么也不能做,只能傻傻等待blocking结束。commonPool中的线程数量一般与当前CPU的核数一致,这样会极大地影响整个JVM的所有ForkJoinTask!
- 任务拆分的粒度不要太大也不要太小。太大的粒度不便于work-stealing发挥实力,太小的粒度又会导致划分的成本比计算本身更高,具体的粒度大小还是需要用户自己来确定。
- 请注意subTask的fork,join顺序。
References
- 《Java并发编程的艺术》 方腾飞
- 聊聊并发(八)——Fork/Join框架介绍
- Java Fork/Join框架