高性能MYSQL读书笔记
总结
第一章介绍了MYSQL数据库的整体架构、以SQL查询为引子,介绍了一条SQL语句整体的执行流程; 引出了数据库的连接、事务、锁等特性;最后介绍了多种存储引擎,简单介绍了这些引擎的实现和功能特点;最后简要介绍了MYSQL的版本历史。
整体架构
MYSQL的整体架构如下图所示
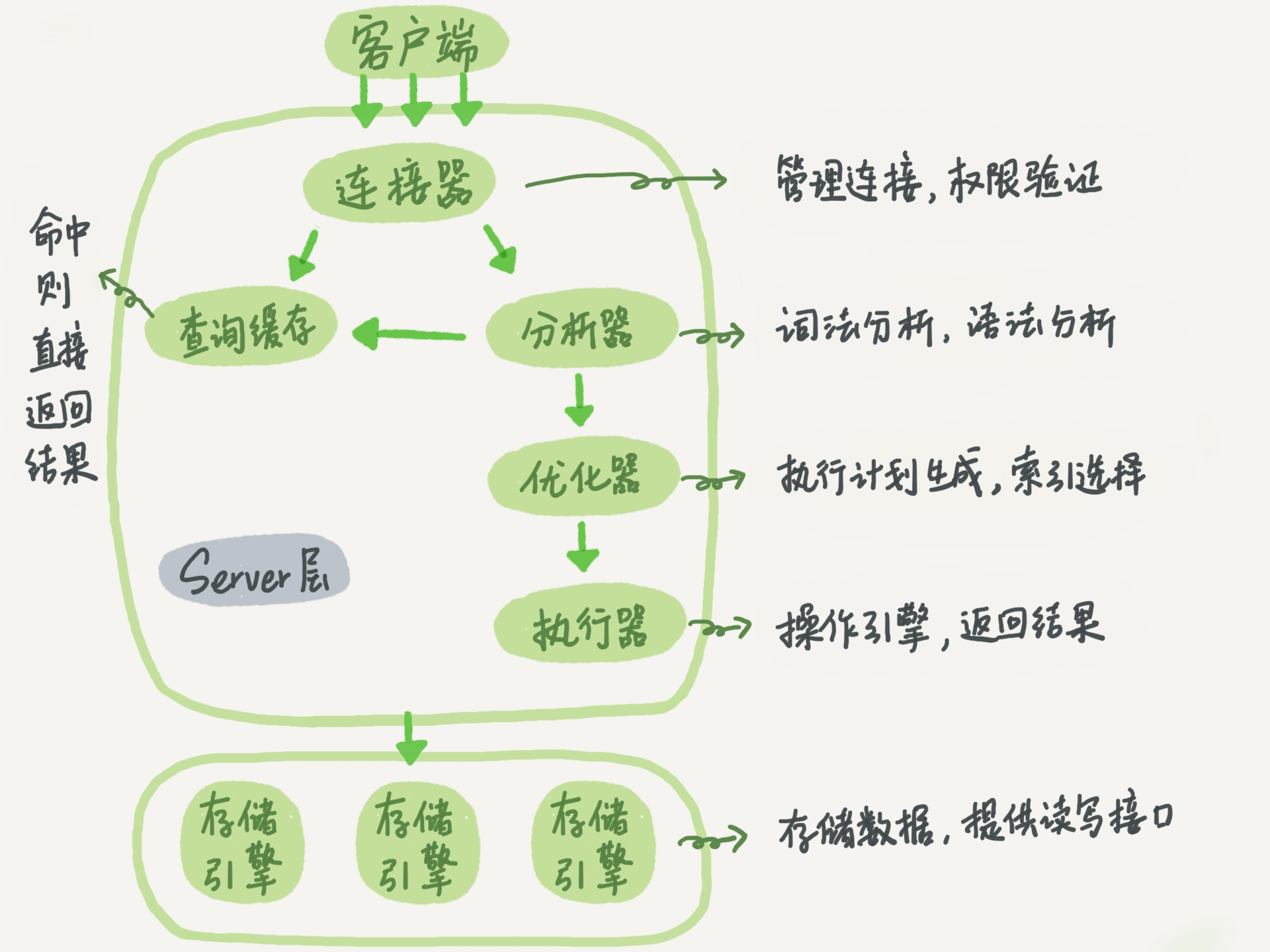
服务层比较特殊,大多数MYSQL的核心服务功能都在这一层,包括所有的内置函数(如日期、时间、数学、加密等)以及所有的跨存储引擎功能:存储过程、触发器、视图等。
连接器
连接器负责权限认证并管理数据库连接的上下文。通常情况下,MYSQL会为每一个connection建立一个单独的线程用于执行其命令,MYSQL5.5版本后开始支持线程池模型。
连接器会根据系统表中的内容验证用户信息,存储用户session信息,支持SSL等相关功能。
极客时间中MYSQL 45讲中提到:数据库链接查询后的内容会缓存在数据库链接对象中,如果一个connection使用后长时间不断开将会导致内存溢出,在MYSQL 5.7.27上测试并未发现该问题。
解析器、优化器以及执行器
SQL语句进入解析器后将被解析为语法树,再由优化器进行优化。优化器在处理时会忽略各存储引擎的不同(API基本相同),但是会根据API所返回的结果(包括统计结果)选择不同的优化策略。执行器根据优化器的结果调用存储引擎API,完成SQL语句的实际执行步骤。
查询缓存
缓存中的查询结果以key-value的形式进行存储,默认情况下查询语句首先会进入缓存中查找数据,但是对于一个表进行更新将导致该表所有缓存都被清空,因此其性能并没有预想中那么高。同时,由于代码层面JDBC框架缓存以及redis等多种缓存技术的应用,使得数据库的cache变得更加鸡肋,MYSQL在8.0版本以后就把缓存相关功能全部去掉了。
Tips:在查询语句中可以手动指定是否使用缓存。
MYSQL中的各种logs
Mysql中含有多种日志文件,常见的有服务层的binlog以及innodb的redolog以及undolog。
BinLog
BinLog由MYSQL的服务层产生,记录了所有引起或可能引起数据库变更的记录。主要作用是数据库备份还原、数据库迁移以及数据库主从同步等。核心本质都是提供语句级别的重放功能,使得多个数据之间数据保持一致。
Binlog通常由两部分组成:mysql-bin.000001数据文件以及mysql-bin.index索引文件,binlog中的数据以事件的形式进行存放,每一条数据包含了开始位置、结束位置、执行的SQL语句以及时间戳等数据。BinLog文件是根据文件大小进行滚动生成的,通过参数max_binlog_size可以指定每个binlog文件的最大大小(由于binlog以event为单位进行记录,遇到超大event时可能会超过该值),通过参数expire_logs_days可以记录binlog自动保存的天数,超过指定时期的binlog将被删除。这里的删除逻辑与kafka中的一样,日志文件将以最后一条记录的时间为准,如果设定的清理时间超过该值将导致整个日志文件都被删掉。
由于binlog主要用于数据库的备份和还原,因此不建议将其与数据放在同一块磁盘上。(不然就一起挂了)
当binlog记录事务信息时,会将数据先写入cache中,cache大小由binlog_cache_size控制,如果空间不足则会继续写入磁盘临时文件中,由参数max_binlog_cache_size控制,如果仍然不够则会抛出错误。与之相对,非事务的binlog则由参数binlog_stmt_cache_size控制。
sync_binlog控制fsync()刷盘的时机,0代表着由操作系统控制,性能最高,但是脏页得不到及时落地,可能导致数据丢失;1代表每一次事务发生后都执行fsync()刷盘操作,安全性最高;n则代表凑满n次事务后进行一次刷盘,兼顾了性能与效率。大多数情况下在主从同步的情况下建议设置为1。
binlog有3种记录格式:
- statement:记录的是mysql原始语句,优点是占用空间少,效率高;缺点是遇到不同版本mysql由于内置函数的不同或者数据库之间存储过程的不同,会导致binlog的回放失败,数据库之间的数据不一致。
- raw:记录的是mysql语句对于每一行记录的具体修改值,优点是兼容性高,避免了statement的缺点,但是占用的磁盘空间非常大,整体效率偏低。
- mix:综合了以上二者的优缺点,平时采用statement记录,某些情况下采用raw格式记录。
RedoLog
引入redolog的主要目的是提升数据库修改效率,将磁盘的随机读写操作转化为顺序读写,大大加快磁盘数据落地的速度。
从日志记录格式来看,与binlog的逻辑语句不同,redolog记录的是’数据文件的修改内容’,是经过解析后的SQL语句对数据库文件的实际修改;redolog记录的数具有幂等性,同一条redolog无论应用多少次对于数据文件的修改结果都是一样的(这是innodb数据恢复的基础之一)。
记录redolog时,MYSQL会按照如下流程依次进行写入:MYSQL用户态logbuffer->操作系统系统系统态buffer->计算机磁盘
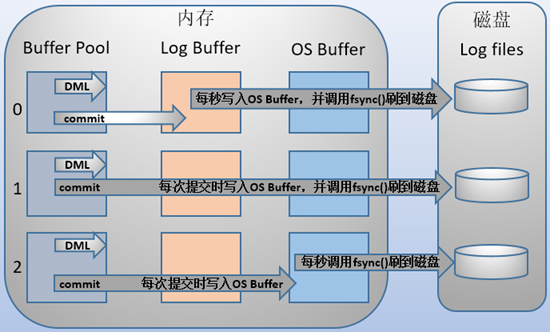
根据MYSQL参数innodb_flush_log_at_trx_commit值的不同,MYSQL对于redolog的处理方式也不一样
- 值为0:事务每次提交时log写入用户态的logbuffer中,程序崩溃或者系统宕机会导致部分数据丢失
- 值为1:事务每次提交时log写入系统buffer,并立即使用fsync()系统调用将其刷入磁盘
- 值为2:事务每次提交时log写入系统buffer,程序崩溃时数据不会丢失,但是系统宕机会导致部分数据丢失。(Kafka所采用的存储方式)
由于内存拷贝与系统刷盘均需要一定时间,因此不同位置处所记录的redolog进度也不一定相同,MYSQL采用了以下几个参数记录不同位置处的redolog进度:
log sequence number记录的是用户态内存中redolog的进度log flushed up to写入os buffer中redolog的进度pages flushed up to已经通过fsync刷入磁盘的redolog进度last checkpoint atcheckpoint当前位置
以上几个值被成为LSN(log sequence number),由于log文件是由用户态内存到系统态内存再到磁盘文件,因此以上几个LSN从上到下依次递减。
当redolog所记录的修改被应用至数据文件之后,redolog的生命周期就完结了,此时mysql就会将checkpoint的值往后推进,表示checkpoint之前的redolog都已被应用至数据文件。
一个mysql进程共享redolog文件(ib_data.log),参数innodb_log_files_in_group可指定redolog文件的数量,参数innodb_log_file_size可指定每一个logfile的大小。mysql总共可记录的logfile数据量约为 每个log文件大小 * log文件数。每个log文件的开头都会留有一定空白用于记录meta信息,当redolog记录达到最后一个log文件的末尾时,MYSQL又会从头开始记录log,类似于ring类型的结构。
undolog
undolog作用主要有两个:1、保证数据库事务的原子性(提供回滚功能);2、保证数据库事务的隔离性(MVCC)。
当数据库启动一个修改事务时,每次修改不仅会记录下对应的redolog,同时也会记录对应的undolog。每一条undolog都是对应redolog的”反操作”,在执行redolog后再执行相对的undolog可使数据恢复至未修改的状态。MYSQL通过创建read view + redolog的方式可以实现RR级别的数据库事务隔离级别;通过链式执行对应redolog同样可以实现回滚操作。
对于不同的操作,undolog的记录方式有所不同:
- insert语句:MYSQL会记录一条对应的delete语句
- delete语句:MYSQL会记录一条对应的insert语句
- update语句: ** 更新列不为主键:直接记录一条与修改相反的update语句 ** 更新列为主键:update将分为两个过程:首先记录一条delete语句,再记录一条insert语句
其中insert的undolog在事务提交/回滚后可立即删除,但是update的undolog却不可以,其他事务可能依赖于此构建历史版本信息。
每行的数据都含有一个隐藏字段:tx_version,事务启动的时候会生成一个read-view(事务的第一条执行语句或者手动指定),通过比对当前活跃的最早事务id、最晚事务id以及当前事务id即可得到当前事务的read-view。
- 目标tx_id == 当前事务id,说明目标处的修改属于当前事务的一部分,可见
- 目标tx_id < 最早事务id,说明目标修改处的事务已先于当前事务诞生而提交,可见
- 目标tx_id > 最晚事务id,说明目标事务启动晚于当前事务诞生,一定不可见
- 最早事务id < 目标tx_id < 最晚事务id,则需要判断目标事务是否在活跃事务集合中,如果在则说明当前事务诞生时目标事务还未commit,不可见;反之,则可见。