HashedWheelTimer原理分析
背景
比如IM等有许多长连接的情况时,需要服务器端一一维护客户端状态。当客户端的数量很大时,可能需要维护大量timer,或者进行低效的扫描。
通常实现方式
轮询扫描
- 使用一个map来记录每一个客户端最后一次与服务器端的通信时间
- 当客户端有数据传输或者心跳报文时,实时更新此Map的值
- 启动一个定时任务,以固定时间间隔对该Map进行轮询扫描:当前时间 - 最后一次通信时间 > 预设超时时间时, client将被标记为超时,被执行超时逻辑。 缺点:当数据较多时,对整个Map进行全量扫描的时间较长,两次扫描之间的时间也会较长,判断连接超时的误差范围较大。
timer跟踪
- 客户端与服务器建立连接后,启动一个watch线程对该链路进行跟踪
- 客户端有数据传输或者心跳报文时,实时更新连接的最后通信时间属性
- watch线程定时扫描:当前时间 - 最后一次通信时间 > 预设超时时间时,client将被标记为超时,watch线程将被标记为超时,被执行超时逻辑 缺点:启动的线程过多,当连接数较大时,watch线程的开销也会非常大,服务器吞吐降低。
WheelTimer核心算法
采用分而治之的思想对轮询扫描法进行优化:将Mao中存放的所有客户端通信记录分散到多个数据结构中,避免了对整个Map进行全量扫描,同时也使得触发的时间间隔大大减小,提高了整体监控的效率以及敏感度。
借助时钟与Hash函数的思想对定时任务进行划分:
- 以任务的触发时间作为hash的key,将所有定时任务分配至若干slot中
- 借助钟表的思想,将slot数组首尾相连,在每个slot代表的时间间隔一定的情况下,遍历整个slot数组的时间固定为n * tickDuration。此时采用slot下标以及所需遍历轮数即可
大致定位任务的触发时间。
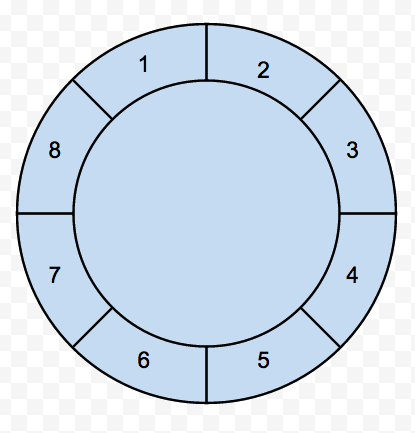
如上图所示,假设每两个slot之间的触发时间为1s,那么遍历整个slot数组的时间为1 * 8 = 8s,一个定时任务将要在60s后触发,60 / 8 = 7 … 4 。那么该定时任务应存放在下标为4的slot中,同时标记其剩余圈数为4。
HashedWheelTimer 实现细节
构造函数与可配置项
HashedWheelTimer最核心的构造函数如下
public HashedWheelTimer(
ThreadFactory threadFactory, //worker线程factory
long tickDuration, //每一tick所代表的时间
TimeUnit unit, //每一tick所代表的时间单位
int ticksPerWheel, //时间轮所含tick数
boolean leakDetection, //泄露检查????
long maxPendingTimeouts)//当前时间轮所允许的最长pending时间,超过该时间的task将被执行reject逻辑
其中ticksPerWheel参数需要注意:1.ticksPerWheel不能大于2的30次方;2.在实际使用中,HashedWheelTimer将采用大于等于设定值的第一个2的整数次方倍作为整个wheel的slot数。
HashedWheelTimer还有一个全局变量用于记录当前jvm中(classloader)实例化了多少个HashedWheelTimer对象,如果超过预设阈值将以log的方式发出警告。
worker线程
HashedWheelTimer的扫描与task.run()方法全部由ThreadFactory生成的Workder线程完成。Worker线程有且仅会存在一个,因此请务必不要向HashedWheelTimer中添加会导致长时间Blocking的任务。
Worker线程会在第一个任务提交或者显式调用start()方法时被启动。(懒加载)其将会一直运行至HashedWheelTimer的stop()方法被调用时为止。
HashedWheelTimer会记录该类被实例化的时间,Worker线程会记录从开始至现在一共所经历的tick数,所有task的延时时将都会根据这两者转化为tick数进行保存。
Timeout与Bucket
所有的定时任务将被实例化为HashedWheelTimout对象存储在每个Tick所对应的Bucket中。
HashedWheelTimeout中主要含有以下属性:
- next/pre 所有timeout对象以双向队列方式进行存储
- remainingRounds 剩余轮数
- status 记录实际要执行的task任务状态
- bucket 自己所属的bucket
HashedWheelBucket则是一个标准的链表结构,使用head与tail指针将属于自己的Timeout对象组织起来。每次遇到新对象插入时,Bucket将把新的对象插入到链表的末尾(tail所指向的位置)
任务的插入与取消
调用newTimeout()方法时,HashedWheelTimer并不会直接将任务放入到目标target中,而是使用一个Queue将这些task缓存起来。当worker线程下一次被唤醒时,将会把Queue里面所缓存的task拿出来,按照时间顺序一一插入到对应的bucket中。
使用Queue作缓存主要有以下几个原因:
- 防止任务被错误添加:假设当前已超过了某task的预设触发时间,那个这个任务被添加至wheel中后会在将来的某个时间被触发,这不符合我们的预期。为了避免这个问题需要处理许多种线程并行的情况,因此干脆直接将这些任务缓存至Queue中,由worker线程定时拉取。
- 减少无效操作:当task在queue中的过程中被标记为cancell,就不再需要将其加入到bucket中,减少CPU无用操作。
task的cancell同样如此,为了避免并发性问题,HashedWheelTimer会将这些任务全部缓存起来,由worker线程定时进行清理。
使用注意事项
- 由于HashedWheelTimer中仅含有一个Worker线程,因此请不要向其中添加可能会长时间阻塞的task,否则会导致后续task无法在预期时间内得到执行。
- 由于GC的原因,使用JAVA所实现的所有Scheduler、Timer的精确性都存在问题。
- HashedWheelTimer无法像ScheduledThreadPoolExecutor一样重复调用某个task,需要用户在task执行完成后手动再次进行添加。(ScheduledTheadPoolExecutor本质上也是这样实现的,只不过添加过程由系统负责)