G1 GC 停顿预测模型
原文地址:http://www.narihiro.info/g1gc-impl-book/scheduling.html
基于历史的预测
所有的预测都是基于历史的拟合。
算术平均值,方差,标准差
HotSpot使用了基于方差与标准差的技术。首先让我们来了解这些术语。 一个班的三个人A,B,C的测试结果回来了。结果如下:
- A:50分
- B:70分
- C:90分
那么,A,B,C测试结果的“平均值”是多少?这很容易。通过以下公式进行计算即可:
(50 + 60 + 90)/ 3 = 70
如上所述,简单地将每个元素相加得到的和除以元素的数量称为算术平均值。这是我们大家最熟悉的平均。
假设你想知道A,B,C有多少偏离参考值。表示这种变化的值被称为标准差。我们这次计算参考值作为算术平均值。
为了查看每个数据的变化,首先需要了解每个数据距参考平均值的距离。只要考虑“每个数据 - 平均值”,就可以获得差异,所以如果将这些差异相加并除以数据的数量,差异似乎就会出现。让我们试一下。
((50-70)+(70-70)+(90-70))/ 3 = 0
它已经变成了0 …… 这是否意味着数据没有变化?但是,A,B,C时显然数据不均匀。
您所做的“每个数据 - 平均值”的错误意味着结果可能是负的。如果是负值,则求和时可能会抵消差值。为了避免负值的情况出现,我们将对每个值进行平方再求和。
((50-70)** 2 +(70-70)** 2 +(90-70)** 2)/ 3 = 266
答案是266。我知道这在某种程度上是不平衡的。像这样的平方数据的总和除以数据的值被称为方差。
由于该值是通过平方得到的值,因此我们计算平方根值。
Math.sqrt(266).to_i#=> 16在小数点后截断
答案是16。该值是前面提到的标准差。标准差是衡量变化的标准。如果标准差很大,则可以判断数据是分散的。如果标准差为0,则可以判断完全没有变化。例如,在这种情况下,如果A,B,C的所有测试结果均为70,则标准差将为0。
衰减平均值
HotSpot虚拟机通过所有历史数据来预测下一次将会得到的值。假设A的过去五次测试结果如下:
- 第一次:30分
- 第二次:35分
- 第三次:40分
- 第四次:42分
- 第五次:50分
那么,我们如何猜测第六次测试的分数呢?
处理历史数据时,HotSpot虚拟机将首先计算衰减平均值。衰减平均值与算术平均值不同,它基于这样一种假设:越早的历史数据对平均值的影响变小。计算方法如下:
davg = 30
davg = 35 * 0.3 + davg * 0.7
davg = 40 * 0.3 + davg * 0.7
davg = 60 * 0.3 + davg * 0.7
davg = 50 * 0.3 + davg * 0.7
davg.to_i#=> 44
设定最近一次的历史记录权重为30%,过去所有历史记录的衰减平均值的权重为70%,最终可以得到衰减平均值。通过以这种方式进行计算,可以减少较早历史数据对于平均值的影响。
为了让它更直观一些,我们来考虑一个例子,其中有十个历史记录和一个单独的评分。然后,在算术平均值的情况下,平均值如下图所示变化。
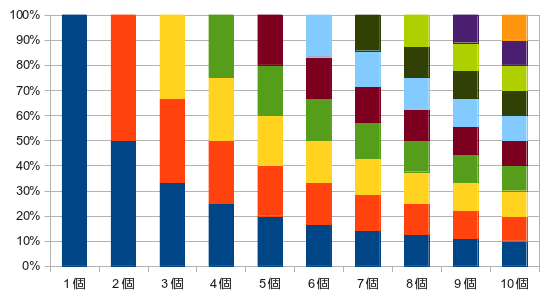
另一方面,在衰减平均值的情况下,其变化下图所示。
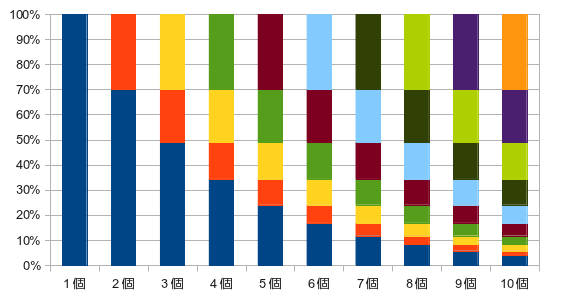
越早的数据在平均值中所占的比例越低,最新的值总是能占平均值权重的30%。
HotSpot采用当前的衰减平均值(davg)作为下一次预测的结果。
随着历史信息数据变老,它与最新数据无关。那么,如何找到降低过去数据(如衰减平均值)影响的平均值就会合适。
衰减方差
我们还将计算一个称为衰减方差的值以及衰减平均值。我们来看看计算方法。
davg = 30
dvar = 0
davg = 35 * 0.3 + davg * 0.7
dvar =((35-davg)** 2)* 0.3 + dvar * 0.7
davg = 40 * 0.3 + davg * 0.7
dvar =((40-davg)** 2)* 0.3 + dvar * 0.7
davg = 42 * 0.3 + davg * 0.7
dvar =((42-davg)** 2)* 0.3 + dvar * 0.7
davg = 50 * 0.3 + davg * 0.7
dvar =((50-davg)** 2)* 0.3 + dvar * 0.7
dvar.to_i#=> 40
衰减方差是实际值距参考值距离的值。这种情况下的参考值是“添加数据时整个历史的衰减平均值”。衰减平均值是预测值(=下次预期)。也就是说,此时的衰减方差表示“实际数据距当时的预测值有多远”。此外,通过以与衰减平均值相同的方式逐渐衰减过去数据的影响来获得衰减方差。
之后,我们得到衰减方差的平方根就是衰减标准偏差。
Math.sqrt(dvar).to_i#=> 6
此处获得的衰减标准差显示预测值与实际数据之间的差异。因此,可以预测,实际值将在预测值的正负6范围内波动。
包含误差的预测值
在HotSpot虚拟机中,该值在一定程度上有些不同。大多数情况下,用户所输入的”安全的预测值”计算方法如下:
预测值包括变化=衰减平均值+(可靠性/ 100 *衰减标准偏差)
这里引入了一个新的词汇:可靠性。可靠性是一个值,表示您相信通过衰减标准差获得的变化范围有多大。例如,如果衰减标准差为6,如果可靠性为100%,则将正值和负值的范围设置为6。如果可靠性为50%,则将其缩小至一半正负3。在HotSpot VM中,此可靠性默认指定为50%,可由用户启动JVM时手动指定。
将可靠范围内的变化的最大值和衰减平均值(预测值)相加,就能得到安全预测值。
44 +(50 / 100.0 * 6)#=> 47.0
例如在HotspotVM的A测试的情况下,A中的下一个测试取47点及以下将被认为是安全的。47就是安全预测值。
实现:记录历史值
让我们看看实现方式。历史记录保存在G1CollectorPolicy的成员变量中,如下所示。
//share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
86: class G1CollectorPolicy: public CollectorPolicy {
150: TruncatedSeq* _concurrent_mark_init_times_ms;
151: TruncatedSeq* _concurrent_mark_remark_times_ms;
152: TruncatedSeq* _concurrent_mark_cleanup_times_ms;
TruncatedSeq是一个继承AbsSeq的类。让我们看看添加历史记录的add()成员函数。
//share/vm/utilities/numberSeq.cpp
36: void AbsSeq::add(double val) {
37: if (_num == 0) {
39: _davg = val;
41: _dvariance = 0.0;
42: } else {
44: _davg = (1.0 - _alpha) * val + _alpha * _davg;
45: double diff = val - _davg;
46: _dvariance = (1.0 - _alpha) * diff * diff + _alpha * _dvariance;
47: }
48: }
_davg是衰减平均值,_davariance是衰减方差。_alpha的默认值是0.7。也就是说,您正在执行的处理与清单12.6中的处理相同。每次将数据添加到历史记录时,都会计算上述成员变量。
让我们看看我们实际将数据添加到历史记录的位置。例如,并发标记的初始标记阶段添加了以下成员函数:
//share/vm/gc_implementation/g1/g1CollectorPolicy.cpp
954: void G1CollectorPolicy::record_concurrent_mark_init_end() {
955: double end_time_sec = os::elapsedTime();
956: double elapsed_time_ms = (end_time_sec - _mark_init_start_sec) * 1000.0;
957: _concurrent_mark_init_times_ms->add(elapsed_time_ms);
961: }
第956行查找初始标记阶段的停止时间,并将该时间添加到第957行的TruncatedSeq。
实现:获取预测值
下面看看获取预测值的部分的处理。查找初始标记阶段的预测值的成员函数如下所示。
//share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
536: double predict_init_time_ms() {
537: return get_new_prediction(_concurrent_mark_init_times_ms);
538: }
537行的get_new_prediction()通过_concurrent_mark_init_times_ms传递成员变量,返回预测值。 get_new_prediction()的定义如下
//share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
342: double get_new_prediction(TruncatedSeq* seq) {
343: return MAX2(seq->davg() + sigma() * seq->dsd(),
344: seq->davg() * confidence_factor(seq->num()));
345: }
MAX2()是一个比较参数并返回大数的函数。当历史记录不足时,采用344行的方式进行处理(引入了可信因子进行处理),因此将省略其解释,并且将仅解释343行处的处理。
davg()返回衰减平均值。sigma()是可靠性。dsd()返回衰减标准差。
并行标记阶段使用
让我们看看在“算法部分4.4停止调度”中描述的GC调度定时sleep的实现。了解了从历史中获取预测值之后这里就变得非常容易理解。
我们将以最后的并行标记阶段为例。
93: void ConcurrentMarkThread::run() {
152: double now = os::elapsedTime();
153: double remark_prediction_ms =
g1_policy->predict_remark_time_ms();
154: jlong sleep_time_ms =
mmu_tracker->when_ms(now, remark_prediction_ms);
155: os::sleep(current_thread, sleep_time_ms, false);
/* 执行最终标记阶段*/
165: CMCheckpointRootsFinalClosure final_cl(_cm);
166: sprintf(verbose_str, "GC remark");
167: VM_CGC_Operation op(&final_cl, verbose_str);
168: VMThread::execute(&op);
第152行的os::elapsedTime()是一个静态成员函数,用于返回自HotspotVM启动以来经过的时间。第153行的predict_remark_time_ms()获取将要发生的最后一个标记阶段的时间的预测值。我们将它传递给when_ms()成员函数。when_ms()使用“算法部分4.4停止调度”中描述的方法返回适当执行时间为止的时间。我们将得到的值传递给第155行的os::sleep(),让并行标记线程sleep到合适的时间。
除了并行标记之外,其他暂停处理方式与上面相同。
Evacuation阶段使用
Evacuation的执行时间由“算法部分5.8 新生代region数量限定”中所述的新生代region的数量决定。由于新生代GC的计算方法相当复杂,因此我们只考虑简单的部分GC的情况。
在部分GC的情况下,必须在可保护GC单位时间的范围内将新生代区域数量上限设置得尽可能小(???感觉应该是大吧 )。使用以下成员函数设置值。
//share/vm/gc_implementation/g1/g1CollectorPolicy.cpp
503: void G1CollectorPolicy::calculate_young_list_min_length() {
504: _young_list_min_length = 0;
505:
509: if (_alloc_rate_ms_seq->num() > 3) {
510: double now_sec = os::elapsedTime();
511: double when_ms = _mmu_tracker->when_max_gc_sec(now_sec) * 1000.0;
512: double alloc_rate_ms = predict_alloc_rate_ms();
513: size_t min_regions = (size_t) ceil(alloc_rate_ms * when_ms);
514: size_t current_region_num = _g1->young_list()->length();
515: _young_list_min_length = min_regions + current_region_num;
516: }
517: }
首先,将当前经过的时间传递给线511上的when_max_gc_sec()以查找直到下一个可停止时间。第512行的Predict_alloc_rate_ms()是预测下一个“分配区域数/经过时间”比率的成员函数。因此alloc_rate_ms * when_ms取整就得到了region的数量。
//share/vm/gc_implementation/g1/g1CollectorPolicy.hpp
379: double predict_alloc_rate_ms() {
380: return get_new_prediction(_alloc_rate_ms_seq);
381: }
_alloc_rate_ms_seq保存过去的“分配区域数/经过时间”的历史,并从历史信息中获得下一个预测值。
然后,Calculate_young_list_min_length() 得到本次将要收集的region数量后,再加上所有的Young Region数量,就是本次MixGC Region的总数量。